
15 min read
Rich called me today. He is a Director of Platform Engineering at a publicly traded company and I am going to leave it at that because the insight matters more than the org chart.
We were talking about testing. Specifically, the Testing Pyramid. The one you have seen in every conference deck for the last fifteen years. Broad base of unit tests. Thinner layer of integration tests. Tiny sliver of end-to-end tests at the top. Usually attributed to Martin Fowler (though Mike Cohn deserves the credit, and honestly Ham Vocke, who wrote the practical version on Fowler’s site, probably deserves it more than either of them).
You know the shape. You have probably drawn it on a whiteboard. You have almost certainly used it to justify why your team does not write more E2E tests.
About halfway through the conversation, Rich said something that reframed the whole discussion for me. “Why does the pyramid look like a pyramid?” I said something about test isolation and fast feedback loops. He cut me off. “No. It looks like a pyramid because of what things cost.”
He was right. That pyramid was never a technical recommendation. It was a financial one.
The shape of the pyramid is the shape of human labor costs.
The Pyramid Is a Budget Document
Think about why the pyramid looks the way it does.
Most readers also read: The Engineers Who Can’t Use AI Agents Don’t Have a Tools Problem
Unit tests are cheap. One engineer writes them alongside the code. They run in milliseconds. They break cleanly. When they fail, you know exactly where to look. A human can maintain hundreds of them without losing their mind.
Integration tests cost more. You need test environments. You need data setup. You need to coordinate across services. When they break, the failure might be in your code or it might be in the contract between your service and someone else’s. A human has to investigate. That takes time.
End-to-end tests are the most expensive. They require full environments, synthetic users, realistic data flows, browser automation, network dependencies, and the patience of someone willing to debug a Selenium script that worked yesterday and fails today because a CSS selector changed three layers deep. One flaky E2E test can burn a day of engineering time. Ten of them can burn a sprint.
So the pyramid says: do less of the expensive thing and more of the cheap thing.
That is not a testing strategy. That is a budget allocation model disguised as engineering wisdom.
E2E Tests Were Always the Best Tests
Nobody says this part out loud.
If you could write an end-to-end test for every permutation of your software, every user path, every edge case, every state transition, every error condition, you would have near-perfect software. You would catch integration failures, regression bugs, data corruption, race conditions, UI inconsistencies, and the subtle behavioral drift that happens when twelve teams ship to the same product surface over eighteen months.
E2E tests are not the worst tests. They are the best tests. They are the tests that most closely mirror what your users actually do.
We just could not afford them.
A team of five QA engineers can maintain maybe two hundred E2E tests before the maintenance burden starts eating their capacity to write new ones. That is the constraint. Not a technical one. A financial one. The pyramid exists because human beings are expensive and E2E test maintenance is a human-capital sinkhole.
Rich and I sat with that for a minute. Then we started talking about car loans.
The Bank of AI
Say you are building the lending platform for the Bank of AI. A customer wants to finance a car, a 2024 Honda Accord, nothing exotic, and pay it off over thirty-six months.
Think about what that workflow actually looks like.
First, the customer creates an account. Username, password, email verification, KYC (Know Your Customer) checks, identity verification, maybe a phone number confirmation. That is its own world. Authentication, authorization, session management, password reset flows, account lockout policies, two-factor setup. Before they have even applied for anything, you have a full domain of complexity.
Then they apply. They fill out the application. Income, employment history, existing debts, the vehicle they want to finance. They upload pay stubs, maybe a W-2, maybe bank statements. The system has to accept those documents, parse them or queue them for review, associate them with the application, and present them to an underwriter or an automated decisioning engine.
Then the decision. Approved, denied, or approved with conditions. Maybe the rate is higher than they wanted. Maybe they need a co-signer. Maybe the system counter-offers a different term length. Each of those branches is its own workflow with its own edge cases.
Then payments. Thirty-six monthly payments. ACH (Automated Clearing House) pulls, payment confirmations, late payment handling, grace periods, fee calculations, payment application logic. Does the payment go to principal first or interest first? What happens when they pay extra one month? What happens when they miss a month?
Then reporting. Monthly statements. Quarterly summaries. Year-end tax documents, the 1098 showing interest paid. Account balance history. Payment history for credit bureau reporting. Each report has its own format, its own regulatory requirements, its own delivery mechanism.
Then payoff. The loan hits zero. The system needs to generate a lien release. File it with the state. Trigger the e-title transfer. Send the customer confirmation. Close the account. Archive the records per retention policy.
That is one product. One car loan. And I have not even mentioned the security audit trail, the compliance logging, the fraud detection signals, or the disaster recovery requirements.
How You Test This Today
In the world the pyramid built, you would never write an end-to-end test that walks a synthetic customer from account creation through thirty-six months of payments to e-title delivery. That test would take minutes to run, require a fully integrated environment with every downstream service available, and break every time someone changed a button label in the payment portal.
So you do the rational thing. You segment.
The identity team writes E2E tests for signup, login, password reset, and account lockout. They mock the lending service. The application team writes E2E tests for the loan application flow. They stub the identity service and the decisioning engine. The payments team tests payment processing with a mocked loan record. The reporting team tests statement generation with synthetic payment histories that never touched a real payment processor.
Each domain has its own test suite. Each suite is manageable. Each suite is also lying to you a little bit.
Because the contract between identity and application? That is a handshake agreement. The shape of the data that flows from decisioning into payments? Someone documented it in Confluence eight months ago (or was it ten?) and it has drifted twice since then. The integration between payment completion and e-title generation? That gets tested manually once a quarter by a QA engineer who knows where the bodies are buried.
You have good unit tests. Decent integration tests. A handful of E2E tests per domain. And a prayer that the seams between domains hold up under real traffic.
The pyramid told you this was fine. The pyramid told you this was the best you could do given the constraints.
The pyramid was right. Given those constraints.
Remove the Constraint
I was explaining how we had segmented the test suites at a previous client (a payments company, similar domain) and Rich just cut through it.
“The entire ratio, units to integration to E2E, that ratio is a human-capital ratio. If you take the human cost out of test maintenance, why would you keep the same ratio?”
I sat with that for a second. “You would not.”
“Right,” he said. “So why are we still building pyramids?”
In an agent-driven world, the cost of writing a test is near zero. The cost of maintaining it is near zero. Generating synthetic data, near zero. Updating tests when the code changes, same story.
You still pay for compute. You still need engineers who understand what the tests should assert and whether a passing test actually means what you think it means. That judgment is not going anywhere.
But the manual labor? The part where a human opens a test file, reads the failure, traces it to a code change three PRs ago, updates the selector, regenerates the fixture, reruns the suite, watches it fail again for a different reason, fixes that too, and commits the whole mess? That part is gone.
Agents handle it in seconds, every time the code changes. Nobody takes a mental health day because the Playwright suite broke again.
So you ask the question again. If you could have any ratio of tests you wanted, unit, integration, contract, end-to-end, performance, chaos, security, and the cost of maintaining each type was roughly equivalent, what shape would your testing strategy be?
Not a pyramid.
A square.
The Testing Square
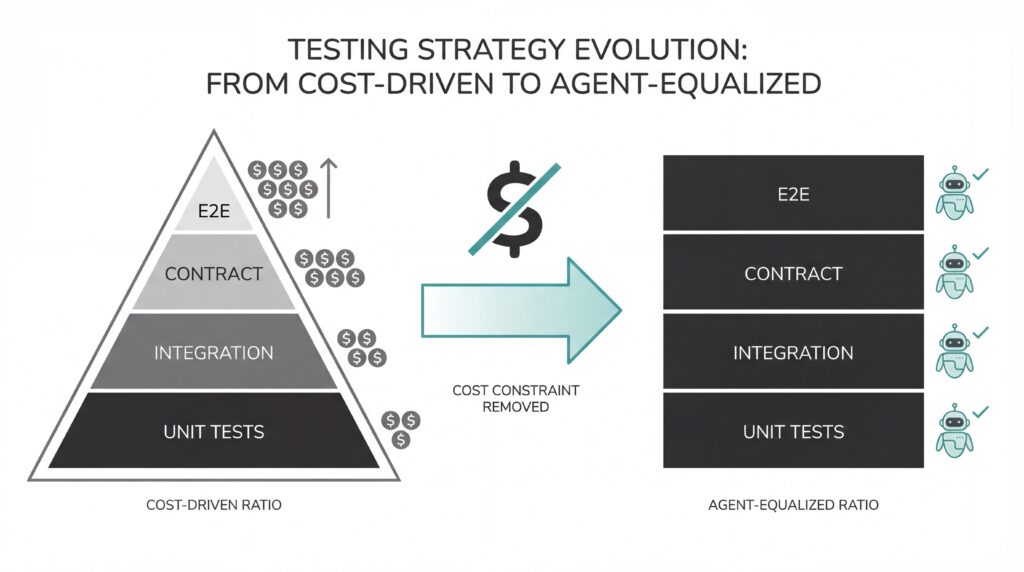 The pyramid was a budget document. The square is what you build when agents remove the cost constraint.
The pyramid was a budget document. The square is what you build when agents remove the cost constraint.
The square is not a metaphor for “write more tests.” It is a different allocation model. You stop rationing the expensive test types because the thing that made them expensive, human maintenance hours, is no longer the binding constraint.
Unit tests, integration tests, contract tests, end-to-end tests, performance tests. Same depth. Same investment. Not because every type matters equally in every scenario, but because you no longer have a reason to starve the ones that used to cost too much.
Go back to the Bank of AI.
In a square model, agents generate and maintain the full unit suite for the payment service. They maintain the integration tests between payments and the loan ledger. They run the contract tests that verify the payment API still matches what reporting expects. They walk a synthetic borrower through the complete thirty-six-month lifecycle, account creation to e-title, in an E2E suite that would have taken a human team a week to build and a month to keep from rotting. And they run performance tests that simulate ten thousand borrowers all making payments on the first of the month.
Now picture a developer fixing a rounding error in how extra payments get applied to principal. Small change. Two lines of code. In the pyramid world, the unit tests pass and everyone moves on. In the square, the agents regenerate the integration tests, verify the contract still holds, run the E2E suite to confirm the fix does not break the year-end 1098, and run the performance suite to make sure the new logic does not introduce a slow query. All of that happens before the PR is reviewed.
That is not a QA process. That is what QA looks like when you stop apologizing for its cost.
The Test Doubles War Is Over
I need to talk about test doubles because if you have spent any time in engineering communities you have watched people fight about this.
Test doubles (mocks, stubs, fakes, spies) are stand-ins for real dependencies. You use a mock instead of calling the actual payment processor. You stub the identity service so your integration test does not depend on a real authentication flow. The practice is as old as automated testing itself, and the arguments about it are nearly as old.
One camp says mock everything. Isolate the unit under test completely. If your test touches a database, a file system, or a network, it is not a unit test. The other camp says mocking hides the bugs that matter most. If you mock the database, you never find out that your ORM generates a query that locks the table for thirty seconds under load. If you stub the payment processor, you never discover that their API changed the shape of the error response and your retry logic now swallows failures silently.
Both camps are right about what they are worried about. Both camps are wrong about the tradeoff being permanent.
The reason the test doubles debate exists at all is that building code for full testability (real services, real data flows, real integrations at every layer) was prohibitively expensive to set up and maintain. So you compromised. You mocked the expensive parts and hoped the seams held. The argument was never really about testing philosophy. It was about how much infrastructure and maintenance time you could afford to throw at the problem.
In the square, agents can build and maintain the code so that it is logically structured for one hundred percent testability. They can spin up the test environments, generate the synthetic data, wire the real services together, and run the full integration without a human spending three days configuring Docker Compose files and writing seed scripts. The agent that writes the payment processing code can also write a test that hits a real (sandboxed) payment processor, verifies the response handling, checks the retry logic, and confirms that the ledger entry matches what reporting expects to consume.
You do not have to choose between isolation and realism anymore. You can have both. Mocks where isolation genuinely matters (testing pure business logic without network latency noise), real integrations everywhere else. The ratio stops being a religious war and starts being an engineering decision, because the cost of either approach is roughly the same when agents are doing the maintenance work.
Rich made the point more bluntly than I would have. “We spent six months arguing about whether to mock Kafka in our integration tests. Six months. The agents do not have opinions about mocking Kafka. They just write both versions and run them.”
Quality Is a Builder’s Game Now
The separate quality organization was built on the same constraint that built the pyramid. Testing was expensive. It required specialized skills. It required dedicated people whose full-time job was to think about what could go wrong and write assertions about it. That was valuable work and I am not dismissing it.
But that work is moving into the build process itself. Quality is becoming something that happens inside the engineering workflow, not something that gets handed off to a separate team after the fact. Agents write the tests as they write the code. They run the tests as they commit. They fix the tests when the code changes. The feedback loop is measured in seconds, not days.
Every handoff is a place where information degrades. If you have ever mapped a value stream, you have seen exactly where these handoffs hide — each one adding days of wait to a cycle that should take hours. You know this. When a developer finishes a feature and hands it to QA, context is lost. Intent is lost. The subtle reasoning behind a design choice does not survive the transition. The QA engineer reads the acceptance criteria, builds a test plan around what was written down, and misses the thing that was never written down because the developer thought it was obvious.
Handoffs kill quality. They always have. We tolerated them because we had no alternative.
Now we do. The agent that writes the code also writes the tests. It has full context. It knows why the code is structured the way it is. It does not need a handoff because there is nothing to hand off. The knowledge and the verification live in the same process.
If your professional identity is built around being the gatekeeper between engineering and production, this should concern you. I wrote about why the separate quality organization expired and the argument is the same one I am making here. Quality is not going away. It matters more than ever. But it is becoming a property of the build process, not a department that reviews the build after it is done.
The engineers who understand quality deeply (the ones who think about edge cases and failure modes and user behavior and data integrity) are more valuable than they have ever been. But they will be embedded in engineering teams, shaping what the agents build and how the agents test, not sitting in a separate org waiting for a handoff that should not exist.
This Is Not Free
Running a full square of tests across every domain of a lending platform costs real money. Compute adds up. Agent orchestration adds up. The engineering time to design the test architecture (deciding what the agents should actually assert and how the domains get segmented) is real work that requires real judgment.
But Rich and I kept coming back to the same question: compared to what?
A production outage during month-end close because the seam between payments and reporting broke and nobody caught it? A compliance finding because the year-end tax documents showed the wrong interest amount for six months? A security incident because the e-title delivery endpoint did not validate the session token and someone walked out with twelve hundred borrowers’ personal data?
The square costs more than having no tests. Obviously. But it is dramatically cheaper than the risk you are carrying right now, with a testing strategy shaped by a budget constraint from 2012.
And it gets you something the pyramid never could. Trust in your pipeline. Real trust. The kind where every commit runs through unit, integration, contract, E2E, and performance tests at equal depth, and you ship because the system told you it was safe. Not because someone on the team said “I think we’re good.”
Your release cadence stops being a negotiation. It becomes a function of how much change your customers can absorb. That is a different problem entirely, and a better one to have.
Fowler Was Not Wrong
Martin Fowler is a serious person and the Testing Pyramid was serious work. I am not dunking on it.
Fowler was not wrong. Cohn was not wrong. The engineers who built testing strategies around the pyramid for the last fifteen years were not wrong. They were constrained. The pyramid was the optimal shape when human engineers had to write, maintain, and debug every test by hand. Given that reality, it was brilliant. It told you how to allocate a scarce resource across test types with wildly different maintenance costs.
But the constraints changed. That is how engineering works. You design for the world you are in, and when the world shifts, the design has to shift with it.
Human capital was the constraint. Agents removed it. The pyramid becomes a square.
What This Means for Your Team
First, a prerequisite. If your quality organization is still writing your tests in 2026, you need to fix that before any of this matters. That model expired in 2014. Developers own tests. Period. Quality is part of the role. It is not a separate division that catches what engineering missed. It is not a gate. It is not a handoff. It is a core competency of every engineer who ships code. If you have not made that transition yet, the square is not your problem. The pyramid is not your problem. Your org design is your problem and you should go fix that first.
If you are leading an engineering organization in 2026 and your testing strategy still looks like a pyramid, you are carrying risk you do not need to carry.
You are making a decision, whether you realize it or not, to under-invest in the test types that catch the most dangerous bugs. Integration failures. Contract drift. End-to-end workflow breaks. Performance degradation under load. These are the defects that take down production, trigger compliance reviews, and erode customer trust. And you are deliberately writing fewer tests for them because fifteen years ago someone told you they were too expensive to maintain.
They were. They are not anymore.
Rich and I ended the call the way most of my calls end. With a plan. He is going to take his platform engineering team and start building the square, domain by domain, starting with the lending lifecycle. Not because it is the easiest place to start. Because it is the highest-risk workflow and the one where the pyramid has been lying to him the longest.
The agents will generate the tests. They will maintain them. They will update the synthetic data when the schemas change and regenerate the fixtures when the business rules shift. The engineers will do what engineers should have been doing all along: deciding what the tests should prove and whether the system deserves their trust.
The pyramid was a compromise. A good one, for its time. The question is whether you are still operating under the constraint that justified it, or whether you are carrying a budget allocation from 2012 into a world that no longer requires it. If your testing strategy still looks like a pyramid in 2026, what exactly are you optimizing for?
Companion


